PII Data Security in a Hybrid and Multicloud World

 Cite this article
Cite this articleData that can be used to uniquely identify a specific individual is considered as Personally Identifiable Information (PII). Common examples that have been traditionally considered as the most sensitive PII data are SSNs, mailing addresses, email addresses, and phone numbers since each can be used to uniquely identify an individual. This emphasizes the need for a reliable and secure cloud based contact center.
However, with an exponential rise in the volume of data collected from social media, mobile devices, websites, and various user tracking technologies, a lot of other secondary data that may not seem like PII data by itself could be used in combination with other sets of collected information to identify an individual through statistical data analytics, AI/ML and many other techniques.
This has put major emphasis on all regulated organizations that deal with PII data to address the following business requirements:
-
Quickly capture and classify data at scale for its sensitivity.
-
Encrypt or de-identify the sensitive data collected before it hits external networks to evade all threat vectors.
-
Apply a zero-trust approach and use least-privilege methods to selectively identify the data based on strict Role-Based Access Control (RBAC).
Common challenges with identification and de-identification of PII data
Security practitioners around the world agree unequivocally that encrypting PII data is the best way to protect it.
However, a major challenge in this approach is capturing and encrypting PII data at scale especially when the source of data could be transient applications such as containers or non-static serverless functions such as AWS Lambda, Azure Functions, etc. More concretely, real-world deployments involving PII data face the following challenges:
-
Applications generating/consuming PII data may not allow code changes, such as SaaS and PaaS applications.
-
Data may go through multiple hops and may need to be quickly identified/de-identified at each hop depending on the business jurisdictions.
-
When large volumes of data (TBs) need to be migrated from on-premises deployments to the cloud, de-identification will be required at a very high rate (~1M ops/s).
-
PII data don’t always adhere to common data types such as SSN, DoB, email address, and existing solutions fall short when it comes to de-identifying or tokenizing data of a more complex or composite format. Furthermore, de-identified or tokenized values oftentimes need to conform to complex formatting requirements. For example, days, months, and years in a tokenized date need to respect certain bounds, to avoid breaking application logic.
Key traits of an effective and practical solution
The ideal solution to keeping PII data protected should address all business challenges outlined above but should also be easily extensible and flexible enough to address future and more complicated data protection requirements. Indeed, when evaluating solutions meant for protecting PII data in global deployments, one should keep these key traits in mind:
-
Cloud-native and multicloud deployment: The gravity of data is being shifted to public clouds. Traditional approaches have supported on-premises hardware-based solutions, which are no longer practical to meet cloud data protection needs for modern applications that are born in the clouds.
-
Hybrid deployment: Organizations and enterprises such as banks, financial institutions, health care providers, large retail segments, and federal agencies generate petabytes of data from on-premises based endpoints. However, to keep up with customer performance demands while following all the necessary security practices these enterprises are gradually moving their business to the clouds, transitioning to a hybrid deployment that can offer a single-pane-of-glass for all applications.
-
Hardware root of trust: Despite billions of cloud-native applications and an ecstatic cloud revolution, hardware root of trust or a general need of Hardware Security Module (HSM) has been and will stay consistently high. The reason is simple – HSMs still offer the best security for keys and cryptographic operations. However, the ideal HSM is one that is genetically integrated with the overall data protection solution.
-
Global Software as a Service (SaaS) offering: Unless and until there are dire compliance restrictions that prohibit organizations from moving to SaaS, the fastest, easiest, and most scalable way to protect data on-premises or in the clouds is by adopting a highly secure, scalable, resilient SaaS-based solution. Even better if such a service is FIPS 140-2 Level 3 certified.
-
Versatility and extensibility: Apart from protecting PII data, security-conscious organizations have adjoining security requirements such as Key Management, Transparent Database Encryption, Secrets Management, Code Signing, VM Encryption, Storage Encryption, Multicloud Key Management, and TLS Certificate Management to name a few. Furthermore, security-related operations should be reachable over a variety of interfaces such as REST API, PKCS#11, KMIP, JCE, Microsoft CAPI, and CNG and SDKs.
A solution that works and objectively solves all real-world use-cases
The Fortanix Data Security Manager (DSM) brings a modern, scalable, lightweight, flexible, and cloud-friendly solution to help customers protect their PII data right at the source, in transit, and at rest. Before we dive into each of the use-cases, let’s recap what DSM offers in summary:
-
Flexible consumption options
a. Available in Cloud Marketplaces with granular core-based pricing to help you get the best ROI.
b. Supports multicloud deployment wherein you can run nodes of a single cluster across different clouds.
c. Supports hybrid cloud deployment wherein you can run a few nodes on-premises and a few nodes in the cloud of your choice as part of the same cluster.
d. Offered as a global SaaS service with FIPS 140-2 Level 3 compliance.
-
One-stop shop for all data protection needs
a. Offers a full suite of data protection services such as Tokenization, Dynamic Data Masking, Key Management, Transparent Data Encryption, Application Encryption, Secrets Management, Key Management for legacy 3rd party HSMs, and Multicloud Key Management.
-
Cluster to cluster peering at group level
a. DSM offers a unique architectural tenet wherein you can selectively use keys from another DSM cluster or another 3rd party HSM while using the same control plane belonging to your primary DSM cluster. This specifically allows you to use the same control plane / URL for all your applications.
This approach also offers a unique advantage in cloud deployments where your primary cluster can be deployed in the cloud, however, some of the highly sensitive cloud applications can perform crypto inside off-the-cloud Fortanix HSMs selectively to meet key residency or localization requirements.
Fortanix’s approach to data de-identification and identification
Fortanix DSM uses the NIST-approved FF1 method to do Format Preserving Encryption to de-identify/tokenize and identify/de-tokenize PII data. The prime advantage and differentiation of Fortanix’s solution rests in how the solution fits within the customer’s complex architecture and can seamlessly perform data identification/de-identification:
-
It can be deployed and consumed at the application host, so data gets de-identified right at the source. This is achieved by caching the key in memory at the application host thereby achieving a very high rate of tokenization and de-tokenization operations per second.
-
It can also sit as a proxy fronting the applications and can transparently de-identify data without needing any code change in client applications. Additionally, it can automatically identify data without a need to pass any key identifier and can integrate with user defined RBAC.
-
For highly sensitive data, if business mandates that data identification/de-identification must happen inside hardware appliances, DSM offers a 3rd approach of streaming data to the centrally deployed DSM cluster for identification/de-identification.
Regardless of business requirements and technical architectural fit, for all the methods mentioned above, the encryption key is always securely stored at rest inside the central DSM cluster. This allows the fulfillment of local key residency requirements since one can control where to deploy a DSM cluster. Example deployments include specific regions in a public cloud offering, on-premises data centers, or a specific region of our SaaS service. Let’s magnify each of the above methods:
DSM Accelerator (DSMA)
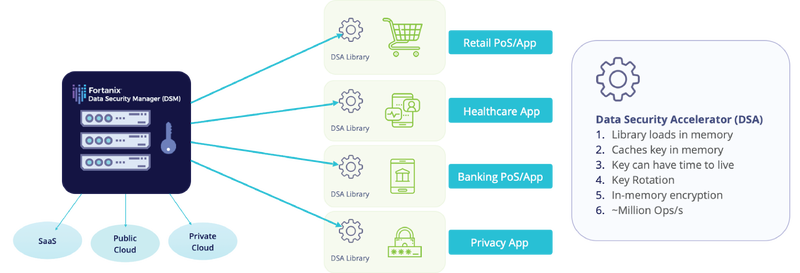
DSM Accelerator (DSMA) is an ideal solution for very high rate data tokenization and de-tokenization with negligible latency. It is offered in a form of a library as Java, JCE, PKCS#11, and as a web service that can be inserted as a container in a mesh of microservices or serverless functions such as AWS Lambda, Azure Functions, etc., for highly scalable/auto-scalable data protection needs.
De-identifying data at the source gives a subpoena-proof approach to de-identifying PII data but requires changes to the application code to insert the tokenize/de-tokenize function calls to DSMA. Sometimes changing the application code is not practical. To address that, we offer another state-of-the-art solution that lets you transparently encrypt your PII data as it hits the network, which we describe next.
Fortanix Transparent Encryption Proxy (TEP)
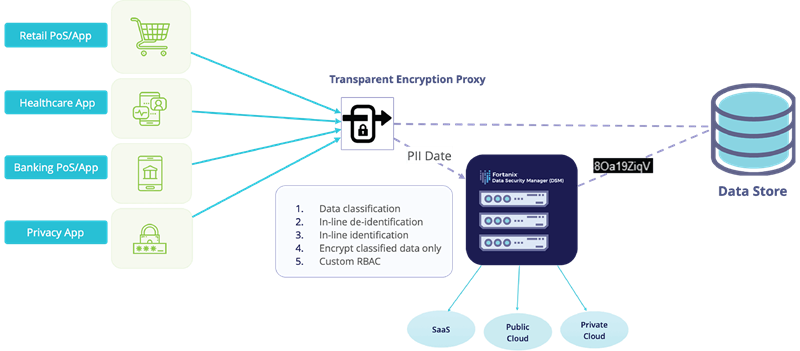
Fortanix Transparent Encryption Proxy (TEP) bundles an Nginx proxy and transparently tokenizes/de-tokenizes data dynamically based on a predefined data classification schema. To make the entire process easier and scalable, data identification/de-tokenization happens automatically using TEP’s intelligent data tagging technology.
This solution also offers a subpoena-proof approach to de-identify PII data right at the source (~almost), however, this approach is ideal for use-cases where data is read and/or written from/to services that are outside of your control such as public SaaS services.
Nevertheless, if very high throughput is needed for data transformation such as bulk or batch de-identification for TBs/PBs of data sitting at rest in data lakes, then DSM Accelerator would be an ideal solution as it can be easily integrated into the data lake or a database-specific User Defined Function (UDF).
De-identifying and Identifying data inside DSM Cluster
Finally, let’s explore the use-case where application code changes are possible, to call external APIs to tokenize/de-tokenize data, but regulations prohibit exporting keys. In such cases, Fortanix offers its versatile approach where all types of operations on your data can be done inside the central DSM cluster.
This is a straightforward solution where a horizontally scalable FIPS 140-2 Level 3 compliant hardware appliance-based solution is either a) deployed in your private cloud or data centers, b) used through our globally deployed SaaS service, or c) deployed as a horizontally and vertically scalable cloud-native container-based cluster or Cloud VM based multi-AZ or multi-region cluster.
Regardless of which approach is employed to solve your PII data protection needs, the definition of data types for tokenization, dynamic data masking policy management, SSO integration with your central Active Directory, and key management is done centrally from a single control plane within your central DSM cluster.
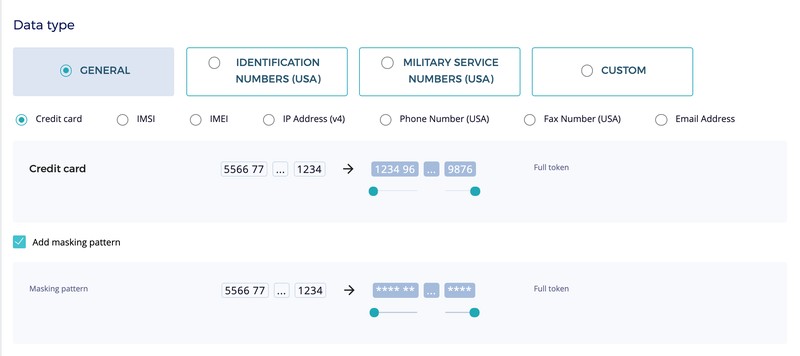
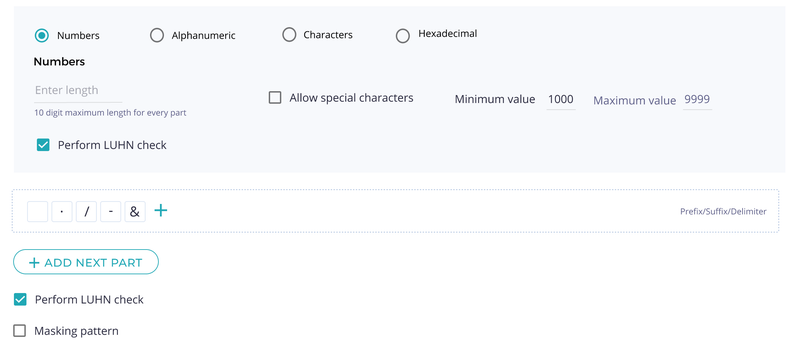
Fortanix DSM offers many commonly used data types out-of-the-box, but occasionally, organizations run into situations where they need to de-identify complex data types that won’t fit any pre-existing data types. To meet such demands, DSM offers a highly customizable token type that can be morphed to meet almost any data format.
The custom token type allows specifying composite types made of multiple sub-parts, with each sub-part having its own format specification. For example, a sub-part can be restricted to numbers only, characters only, etc.
To cater to more complex needs, numeric sub-parts can be further restricted to a range of integer values. The custom token type is much more versatile than what this example shows and can express many more complex use-uses.
Key takeaways
-
Fortanix can effectively protect any type of PII data at scale at the source, in transit, or at rest.
-
Whether you need an auto-scalable cloud-native solution, a globally deployed SaaS solution, or a self-managed air-gapped HSM grade on-premises solution, we have you covered.
-
Fortanix is a Data-first Multicloud security company and can deterministically help you protect PII data across public and private clouds and SaaS services.






